延续前两篇的讨论,fiisual 的 2026 展望系列文也来到第三部,还没看过前几篇的朋友也可以先参考看看。
2026 展望系列文 part 1 - 全球经济体在 AI 影响下的下一步
重点产业二:散热

散热产业为另一个 2026 年将进入高速成长的产业。在 AI 推动下,晶片性能快速升级,TDP 持续攀高,使散热系统的重要性明显提升。随着高耗能的 GB300 GPU 于 2026 年正式量产放量,AI 伺服器将全面转向更高热流密度的散热架构,液冷成为主流,并推动水冷板、QD(液冷快接头)、歧管与 CDU(冷却液分配装置) 等关键液冷组件进入实质加速成长期。
散热设计功耗(Thermal Design Power,TDP) 指电脑处理器或元件在标准运作负载下的最大散热需求,散热系统必须能够处理这个功耗以防止元件过热。
散热产业来到技术转折点:液冷将成为主流趋势
散热产业过去主要应用于一般伺服器与 PC 的气冷模组,属于技术与需求相对成熟的领域。然而,随着 AI 应用蓬勃发展,高功耗晶片与高密度机柜快速普及,散热系统的重要性大幅提升,其角色已从配角转为 AI 基础建设的关键环节,如何在有限电力与空间条件下,让高功耗晶片稳定运转、维持长时间高负载下的效能与可靠性,同时提升整体资料中心能效,已成为散热产业面临的核心课题。
散热技术加速转型,液冷成为主流趋势
散热方案依原理可分为气冷与液冷两大类,其中液冷又因应用场景不同,衍生出冷板、浸没式、两相液冷等多种形式。 随着 AI 晶片与资料中心运算密度迅速提升、功耗不断上探,高性能伺服器对散热效率的要求大幅提高,传统气冷逐渐达到物理极限,散热厂商逐渐朝液冷散热转型,成为支撑下一世代 AI 基础设施的关键技术路线。
气冷与液冷散热比较 | | 气冷 | 液冷 | | --- | --- | --- | | TDP | 250W-500W | 700W-5,000W | | 散热效率 | 中,需大量风扇 | 高,直接带走热源 | | PUE | 较高 | 较低,可节省 20%-40% | | 噪音 | 高 | 低 | | 空间需求 | 大,随 TDP 上升需要更多风道与更大散热模组 | 低,模组紧凑、可增加机柜密度 | | 成本 | 低 | 高 | | 应用 | 一般伺服器、记忆体、网通、PC | AI 伺服器 |
气冷散热以气流排热,惟在 AI 高功耗时代面临效能上限
气冷散热是目前通用伺服器与 PC 最普遍采用的散热方式,主要由散热模组(如鳍片、热导管、均热片)搭配风扇系统组成,透过强制气流将晶片热量带离系统。 由于技术成熟、成本低、维护便利,气冷长期广泛应用于一般伺服器、网通设备与 PC,也是双鸿、奇𬭎、建准等台厂的核心产品线。然而,随着 AI GPU/ASIC 功耗快速攀升至 700W、1,000W,甚至朝 2,000–3,000W 发展,气冷散热的物理瓶颈日益明显:提高风量需依赖更高速风扇,造成噪音、耗能与散热效率的边际效益递减;更关键的是,气冷无法有效处理超高热流密度,容易使晶片在高负载下降频、影响效能与系统可靠性。
液冷高比热及高导热效率优势成为 AI 伺服器主流散热方案
液冷散热原理是透过冷却液在水冷板微流道中循环,直接从热源带走热量,再由 CDU/Sidecar 将热排至外部冷却设备。 相较于气流,液体具更高的比热容量与导热效率,使液冷能处理远高于气冷的热流密度,散热能力可支援 700W 甚至高达 3,000–5,000W 的 TDP,成为 AI 伺服器高速成长下最核心的散热技术。 随着 AI 模型越趋庞大、GPU 配置更密集、资料中心追求更低 PUE,液冷不仅可提升热交换效率、降低能耗,还能让机房在相同电力与空间限制下容纳更多算力。然而,液冷的导入也伴随较高的系统成本与整合复杂度,需依赖水冷板、微流道、快接头、CDU、管路等多项关键零组件,并对防漏设计、冷却液洁净度管理以及整体机房冷却架构提出更高要求。
散热方案新架构:液冷主导核心散热,气冷转为区域双轨并存
随着主流 AI 伺服器逐步转向液冷散热,液冷的重要性快速提升。但即使伺服器导入液冷,高功耗 AI 加速卡以外的其他零组件如 VRM、记忆体、SSD、网卡、PCB 热点等仍需依靠风扇与气冷模组排出残余热量。 因此,气冷并不会因液冷普及而消失,而是从主要散热方案转为辅助散热角色,负责处理较低功耗的区域热源;相反地,AI GPU/ASIC 等高功耗载板的核心散热则将由液冷全面取代。整体来看,未来资料中心将形成「液冷负责主热源、气冷负责周边热源」的双轨并存架构,成为 AI 时代散热系统的基本运作模式。
2026 液冷散热迎高成长:GB300 + ASIC 双驱动
GB300 放量成为 2026 年散热产业的核心成长动能
GPU 因功耗高、热流密度极大,相较 ASIC 更早迈入液冷散热世代。随着 NVIDIA 自 2026 年起进入 GB300 大规模放量期,AI 伺服器散热架构也将从 GB200 时代混合式散热正式过渡到全面以 Direct-to-Chip 液冷为主的架构,带动液冷产业迎来快速扩张。
TDP 持续攀升,GB300 散热架构全面升级,液冷内含价值大幅提高
随着散热效率提升并额外导入 CPX(Cooling Performance Extension),GB300 GPU 的 TDP 已推升至近 2,000W,完全超出气冷所能处理的热流密度,使伺服器级液冷从过去仅见于高阶机种,正式在 GB300 世代由选配走向标配。在此架构升级下,水冷板(cold plate)、分歧管(manifold)、快接头(QD)、CDU/Sidecar 与管路等液冷组件的用量与价值全面提高。 以水冷板与 QD 为例,GB200 单柜约需 96–108 片水冷板与约 360 个 QD,而 GB300 因散热流量与热通量需求更高,冷板与 QD 数量均上调,且交换托盘水冷板大幅增加,使单柜液冷 BOM 价值比 GB200 再提升约 10–30%。整体而言,AI 训练机柜的液冷内含价值已由传统伺服器的数百美元,提升至每柜 2–3 万美元等级,成为散热供应链在 2026 年进入高速成长的重要成长动能。
| GB200 NVL72 | GB300 NVL72 | ||
|---|---|---|---|
| cold plate (片) | 99 | 117 | +18% |
| QD (颗) | 360 | 576 | +220% |
| cold plate + QD value (整柜) | $ 23,490 | $ 30,870 | +31% |
备注:GB200 与 GB300 液冷零组件内含价值比较(CSP 客制化后每家用量不同)。资料来源:凯基证券
GB300 量产带动液冷零组件出货同步增加
2025 年 Blackwell 平台的整体出货节奏仍以 GB200 NVL72 为主,GB300 虽已进入工程样品阶段并开始少量出货,但在全年 NVL72 机柜组合中的占比有限。进入 2026 年后,GB300 将正式跨入量产与放量周期,成为新一代高功耗、高热流密度 AI 训练伺服器的核心平台,带动 AI 训练伺服器全面转向更高功耗、高热密度的硬体架构,并使液冷成为主流散热路线。
从出货量推估,2025 年 GB200+GB300 合计约 2.3–2.5 万柜;随着 GB300 于 2026 年大幅放量,整体 NVL72 出货有望提升至 5.5–6.0 万柜,YoY 约 +130%。值得关注的是,2026 年的增量几乎完全由 GB300 贡献,而 GB300 载板 TDP 跃升至近 2,000W 并搭配 CPX 架构,其液冷散热配置全面升级,使单柜液冷 BOM 价值相较 GB200 再提升约 10–20%。
整体而言,GB300 的放量代表 AI 伺服器正式进入液冷主导的世代。随着水冷板、QD、manifold、CDU 等液冷关键零组件用量与规格同步提升,2026 年液冷散热供应链的实质成长将带动整体产业进入高速成长期。
ASIC 液冷渗透率自 2026 起快速拉升,为散热产业另一成长动能
AI ASIC 虽以高效能、低功耗为特性,但随着大型推论模型规模持续膨胀,其热流密度已快速逼近气冷极限。 预估至 2026 年 ASIC 晶片 TDP 将迈向 1,000W 门槛,此后气冷已难以处理高热通量,因此尽管 2025 年市场尚未出现单颗突破 1,000W 的 ASIC,主流 CSP 已提前完成液冷基础设施部署,为下一阶段高功率 ASIC 做散热准备。
以最早导入液冷散热的 CSP 厂商 AWS 为例:Trainium 2 仍采 VC 气冷,而 2025 年推出的改良版 Trainium 2.5 已首度导入少量液冷机柜验证,将于 2Q26 量产的 Trainium 3 则正式采用液冷散热,液冷渗透率将快速提高。 虽然 Trainium 3 的 TDP 尚未全面跨越 1,000W,但高密度部署需求已使部分机柜必须导入液冷,显示气冷散热已遇到结构性瓶颈。同样地,Google TPU v6、Meta MTIA 2 也将推出液冷版本,进一步确立 ASIC 液冷化的不可逆趋势。
在系统级架构上,CSP 的自研 ASIC 伺服器多采类 GPU 伺服器的整柜式设计,使运算层与交换器层的 cold plate 与 QD 用量大幅提升。 根据 Morgan Stanley 与凯基资料均指出,2026 年 ASIC 导入液冷后,其液冷零组件内含价值将接近甚至逼近 GPU 伺服器水准,使 ASIC 散热成为继 GB300 之后散热供应链的第二条结构性成长主轴。
整体而言,2026 年将是 AI ASIC 液冷渗透率由低转高的关键拐点。在 TDP 持续上升、CSP 完成水冷机柜与水路部署、AWS/Google/Meta 下一代 ASIC 全面支援液冷的多重推动下,ASIC 液冷散热需求将快速扩张。这将带动 water block、 QD、 manifold、 CDU 等液冷零组件全面成长,使 2026 年散热产业进入由 GB300 + ASIC 双主线驱动的高速扩张期。
Micro-channel Lid 技术尚未成熟,预估 2027 年导入
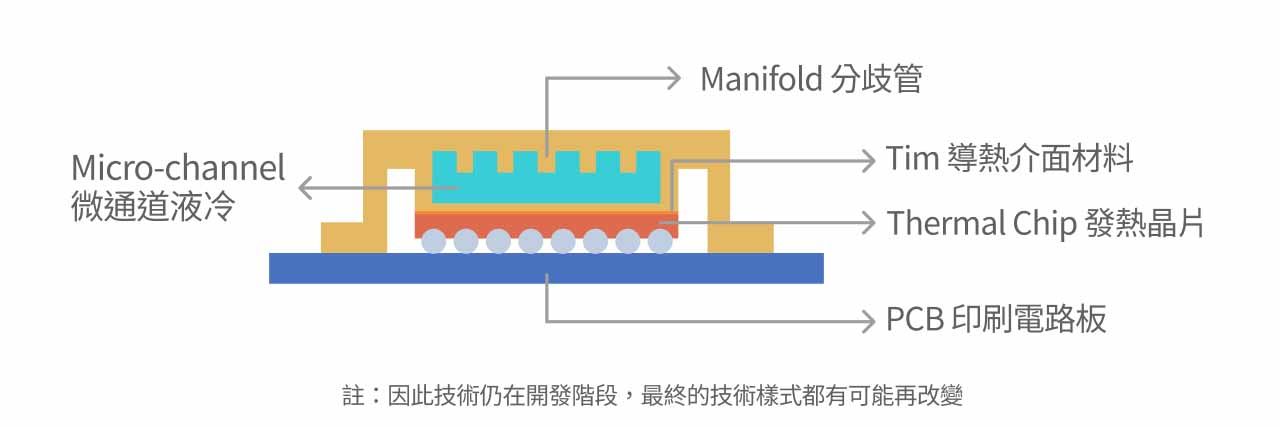
随着模型规模快速膨胀、AI 训练与推论晶片 TDP 不断提升,仅依赖外部冷板的散热方案已逼近技术极限,散热厂商发展出更先进散热技术,Micro-channel Lid( MCL)为下一代最有机会导入的散热技术。
MCL 为晶片级液冷散热中最先进的技术形式,其核心概念是将微流道直接制作在晶片封装上盖,使冷却液能于晶片表面上方进行直接对流散热。 相较于传统冷板或微流道冷板(MCCP),MCL 能提供更高的热通量处理能力,热阻更低,并能将散热介面距离从封装层大幅缩短到贴近晶片本体,因此能支援未来高达 1,500–2,000W 的超高功率 AI GPU 与 AI ASIC,包括下一代 GPU 及多数 CSP 自研 ASIC在规格规划上都已评估导入晶片级散热。相较于传统 liquid cold plate, MCL 的散热效率更高、热通量处理能力可达 200–400 W/cm²,并能在高密度整柜架构下与系统级液冷共同降低整机热阻,是因应下一代 AI 加速器功耗上升的重要散热路线。
然而,尽管 MCL 技术路线明确,其量产门槛远高于现行冷板技术。MCL 需要微细加工、超高洁净度制程、与晶片封装厂密切协作,并必须在不影响封装可靠度的前提下导入液体流体通道,技术风险与制程复杂度显著高于现行 cold plate。MCL 目前仍处于技术验证与 prototype 阶段,尚未准备好支援大规模 AI 加速器量产。此外,CSP 与 GPU 厂商的 liquid cooling roadmap 显示,2025–2026 年仍以cold plate 与 MCCP 为主流散热解决方案。
在技术成熟度、制程整合与产能建置的限制下,现阶段 MCL 尚未具备商用量产条件,市场共识均预估 MCL 将最快于 2027 年起,由下一代 GPU 与新一代高功率 ASIC 开始小规模导入。届时晶片级液冷将与 MCCP 形成互补关系,共同支援 2,000W 级 AI 加速器的散热需求。
台湾焦点个股
2026 年将成为散热产业的关键成长年份,供应链大致可分为上游 IC/系统端、中游液冷/气冷零组件与系统整合、以及下游机柜组装三大区块。其中台湾厂商主要分布于中下游,提供水冷板、 QD 、 manifold、 CDU 等液冷关键零组件与整柜系统整合服务。展望 2026 年,散热产业的成长动能将来自两大方向:1. 液冷零组件单柜内含价值显著提升以及 2. 液冷散热机柜出货量倍增。此外,由于液冷产品对可靠度要求极高,过去外漏风险使 CSP 更倾向与既有供应商深化合作,因此已取得 NVIDIA/CSP 认证与导入经验的台湾液冷零组件公司,将成为 2026 年散热产业最具可见度、最具结构性受惠的族群。
奇𬭎(3017.TW)
奇𬭎为台湾散热产业龙头,横跨气冷、液冷与整机柜散热系统,具备从 DC/AC 风扇、cold plate、 MCCP、manifold 到整体液冷解决方案的完整产品线。其核心竞争力主要来自两点:1. 垂直整合能力完备、量产经验深厚,能有效承接高复杂度液冷模组;2. 与 NVIDIA、AMD 及主要 CSP 长期合作,在 GB200/GB300 GPU 水冷模组与多款 AI ASIC 液冷专案中具高度黏着度,使其在新一代液冷架构中取得明显先行者优势。
展望 2026 年,奇𬭎将迎来三大成长动能:
- NVIDIA GB300 自 2026 年起进入大规模放量,冷板、MCCP 与分歧管的内含价值均较 GB200 明显提升,带动液冷散热营收高速成长
- 取得多数 CSP ASIC 订单,从 2026 年起陆续导入,推升水冷板、歧管与 O-Rack 液冷系统需求
- 越南厂新增产能于 2025–2026 年逐步开出,使奇𬭎能承接更高比重的液冷模组订单。
整体而言,奇𬭎凭借完整产品版图、成熟量产能力、跨国产能配置,以及与 Tier-1 GPU/CSP 客户的长期深度合作关系,奇𬭎有望在 2026 年 GB300+ASIC 双主线带动下迎来营运大幅成长,并持续巩固其作为台湾液冷散热供应链核心领先者的地位。
富世达(6805.TW)
富世达为台湾精密轴承供应商,早期以消费性电子轴承为核心本业,其中折叠手机轴承为主要营收来源,并与中国与韩系折叠手机品牌维持长期合作关系。受惠于折叠手机渗透率提升与新机种增加,富世达在精密加工、耐用度设计与高可靠度转轴技术上建立明显竞争优势,成为全球折叠手机供应链中不可替代的精密轴承厂商之一。
在既有轴承本业之外,富世达近年积极切入 AI 伺服器液冷散热领域,是全球少数具备高可靠度 QD 量产能力的厂商。公司产品广泛应用于资料中心、AI 加速器、伺服器整柜液冷系统,并已通过多家 Tier-1 CSP 认证。其竞争优势来自:
- 精密加工、耐压测试、气密封装等关键制程能力完整
- 液冷接头具高耐压、高流量、高可靠度,规格升级速度领先同业
- 与奇𬭎等主要液冷模组厂合作紧密,掌握 AI 液冷散热渗透率提升所带来的采购动能。
展望 2026 年,富世达将同时受惠于折叠手机量能回升及 AI 液冷散热加速成长两大结构性驱动:
- 折叠手机出货回温、新机型增加与转轴规格升级,带动高阶轴承需求延续成长
- NVIDIA GB300 放量使单柜 QD 使用量明显提升,推升液冷零组件 ASP
- CSP 自研 ASIC 自 2026 年起大幅采用液冷,带动系统级液冷回路中 QD 用量大增。
整体而言,富世达兼具折叠手机精密轴承的既有龙头地位与 AI 液冷散热零组件的强势切入能力,在折叠手机复苏+液冷爆发两大成长动能带动下,2026 年有望迎来营运加速成长期,成为台湾液冷与精密机构件领域兼具成长性的代表企业。
