随着 AI 模型发展重心由训练逐步转向推论,GPU 与 ASIC 晶片的功耗、封装尺寸与热密度同步攀升,带动晶片 TDP 持续上行。若热能无法即时有效导出,将可能导致伺服器频繁发生跳机、降频,甚至影响整体系统稳定性。以 NVIDIA 为例,单颗 B300 晶片 TDP 已达 1,400W,预计于 2026 年下半年推出的 Rubin 将进一步提升至 2,300W,而 2027 年推出的 Rubin Ultra 单颗晶片 TDP 甚至可能突破 3,000W。在此趋势下,GPU 伺服器散热架构正由传统气冷加速转向直接液冷方案,后者亦成为当前散热产业最具成长性的核心方向。
技术背景:散热技术提升但仍不足
NVIDIA GPU Package、 伺服器机柜之 TDP 及散热方案
| 架构 | Ampere | Hopper | Blackwell | Blackwell Ultra | Rubin | Rubin Ultra | Feynman |
|---|---|---|---|---|---|---|---|
| TDP | 400W | 700W | 1200W | 1400W | 2300W | 3000W+ | 4000W+ |
| 散热方案 | Air-Cooling | Air-Cooling | DLC | DLC | DLC | DLC | Immersion Cooling |
| 导入时间 | 2020 | 2022 | 2024 | 2025 下半年 | 2026 下半年 | 2027 下半年 | 2028 |
| 代表产品 | A100 | H100/H200 | B200/GB200 | B300 | Rubin GPU | Rubin Ultra | Feynman GPU |
| 机柜架构 | GB200 NVL72 | GB300 NVL72 | VR200 NVL144 | ||||
| 单柜 TDP | 120-130kW | 130-140kW | <225KW | ||||
| 散热方案 | Liquid(85%)+Air(15%) | Liquid(85%)+Air(15%) | Liquid(100%) |
传统气冷转向水冷板仍难以满足高功耗晶片散热需求
传统气冷方案透过风扇与导风道带走热能,结构简便且成本相对低廉,但散热能力受限于风扇风量与鳍片面积,这导致气冷在高功率密度运算环境中的散热效率明显受限,因此气冷主要适用于低至中等功率伺服器,难以支援超过约 1,000W 的 TDP。
为改善气冷散热能力但仍保留既有设计,业界衍伸出了「水对气散热方案」,此方案通常透过液体辅助空气冷却,热传路径通常为晶片热量先由散热鳍片传递至空气,再由水冷热交换器将空气中的热量带入水循环系统并排至资料中心外部,由于水在系统中承担主要的热量搬运功能,因此整体散热能力显著提升,使其可支援约 850–1,200W TDP,水对气方案最大的优势在于与既有伺服器架构高度相容,且仍然采用传统气冷散热器与风扇,因此资料中心不需大幅修改伺服器硬体设计即可提高散热能力,这使其成为 AI 资料中心初期升级的重要过渡方案。然而,此技术的根本限制在于热传导路径中仍包含空气介质,使其在高功耗环境下仍容易受到气流效率与局部热点问题限制,因此 L2A 普遍被视为一种过渡方案,因其无法支援 TDP 超过 1,200W 的 Al 伺服器。
目前主流的「水对水散热方案」移除机柜内部的风扇构造,冷却液透过冷板(cold plate)直接接触晶片封装,晶片产生的热量经由导热介面材料(TIM)传导至冷板,再由冷却液带走并送至冷却分配单元(CDU)与资料中心水系统进行热交换,使热量大部分保留在液体回路中,显著降低对机架的热负载。 虽然热导率高于气冷方案,但液冷板通常在散热板底部或片侧布置管路,热能的传导仍需经过均热板、TIM 等多个介面,热阻链较长,当 GPU 功耗进一步攀升至约 2000W 以上时,介面热阻将成为散热瓶颈, 传统单相水冷板将逼近极限。
| 技术细分 | 一般气冷 | 水对气 | 水对水 |
|---|---|---|---|
| TDP | 500–1000W | 850–1200W | 1200–1500W |
| PUE | 1.5–1.7 | 1.07–1.3 | 1.07–1.3 |
| 优点 | 成本低、技术成熟、维护简单 | 混合冷却、可靠度高 | 高散热效率,适合高热密度 |
| 缺点 | 无法支援高功耗、噪音污染 | 成本较高、需专业维护 | 初期建置成本高、需 Facility Loop 改造 |
| 预期商用时间 | 已成熟,逐步被水冷取代 | 2024A–2027F 成长期 | 2025E–2030F 主流 |
| 终端应用举例 | AMD EPYC Genoa / Bergamo、NVIDIA A100 PCIe | 高效能伺服器、部分 AI 应用 | NVIDIA DGX H100 / GB200 NVL72 |
微通道液冷板(MCCP)技术介绍
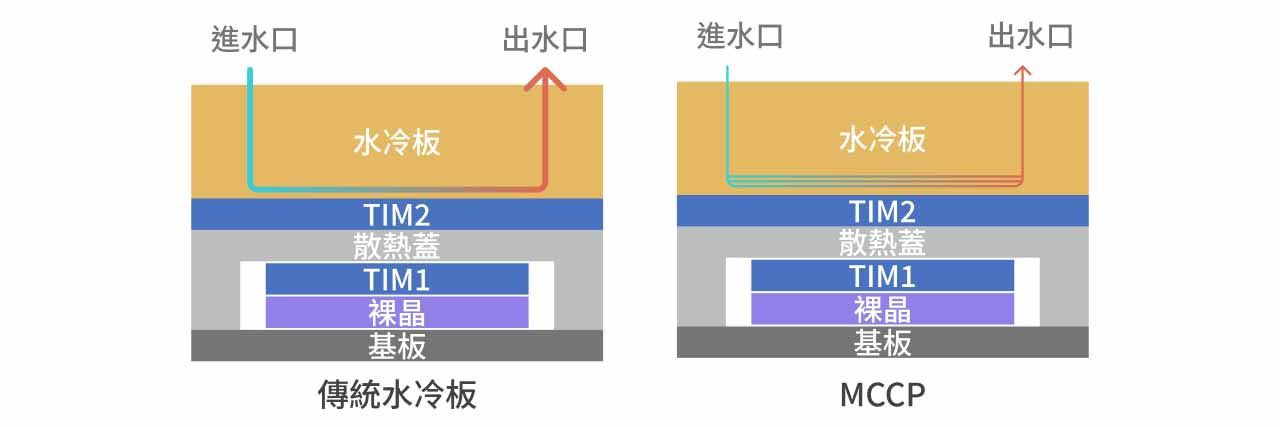
由于传统水冷板逐步逼近散热物理极限,业界开始导入 MCCP(Micro Channel Cold Plate)作为改良方案。 两者在整体封装架构上大致相同,皆维持 TIM 1、Heat Spreader、TIM 2 与 Cold Plate 的四层结构,差异主要在于 Cold Plate 内部流道设计的进一步优化。
传统 Cold Plate 的内部水道采宏观通道设计,通道宽度约 150 μm,冷却液与金属壁面的接触面积有限,换热效率受制于流体对流边界层,在 AI 晶片功耗持续攀升的趋势下逐渐力不从心。MCCP 的改良逻辑直接且精准:在不动封装架构的前提下,将 Cold Plate 内部通道缩窄至 80–100 μm,通道数量对应增加,冷却液与金属壁面的总接触面积大幅提升,换热效率因此提高约 1 倍,可应对 Vera Rubin R100 约 1.8 kW 的功耗需求。
MCCP 之所以能幅提升换热效率,关键在于其内部的微流体工程设计。 若我们将微通道水冷板进行内部透视,便能窥见其核心的热力学引擎。冷却液从 Inlet 注入盖板后,并非单纯流过一个空腔,而是被强制导流进入由高精度金属加工所打造的微通道中。
整个散热载体建立于具备极佳热传导率的金属底之上,其底部紧密贴附于下方之发热源。在底板上方,工程人员透过极高精度的机械加工技术,建构出密集且平行的散热鳍片。这些相邻鳍片之间所形成的微小狭长空间,即为冷却液流窜的微流道。
在流体动力运作机制上,冷却液流由模组一端注入,沿着平行的流动方向快速穿梭于微通道阵列中。由于微型鳍片的设计将金属与液体的接触表面积较大,冷却液得以透过高效的强制对流,将底板传导上来的巨量晶片废热迅速带走。
微通道盖板(MCL)技术介绍
MCCP 可支撑目前需求,业界加速研发 MCL 以因应更高功耗挑战
MCCP 的核心价值在于以最小的架构改动换取最快的导入速度,是散热产业在 MCL 量产就绪之前的关键过渡方案。 然而 TIM 2 导热系数仅 2–7 W/m·K、占整体热阻 70% 以上的根本瓶颈并未被解决,面对 2027 年后 AI 晶片突破 2,000W 甚至 3,000W 的功耗预期,MCCP 的改良空间已趋近上限。
| 散热层级与材料类型 | 热传导率 (W/m·K) | 物理特性与影响 | 应用情境与痛点 |
|---|---|---|---|
| 矽晶片(SoC, HBM) | 130 - 150 | 单晶结构,声子传导极佳 | 高功率下产生极端热点 |
| TIM1(液态金属、银胶) | 40 - 80 | 极高导热性,需处理裸片级高热通量 | 随温度循环易产生泵出效应 ,导致空洞与失效 |
| 均热片 (无氧铜) | ~400 | 极佳热传导与热扩散能力 | 增加整体封装体积、重量与热传递路径长度 |
| TIM2 (导热膏、相变材料) | 2 - 7 | 低导热性,提供表面贴合与机械缓冲 | 整体架构中热阻最高的一环,常占据总热阻的 70% 以上 |
| 水冷板 (金属) | 200 - 400 | 具备宏观水道,与液体进行对流热交换 | 流体对流边界层限制了最终热交换效率 |
此架构的核心瓶颈在于 TIM2 的存在:高阶 TIM2 的热传导率通常仅约 2 至 7 W/m·K,与金属铜约 400 W/m·K 的导热能力相比,仍存在近百倍差距。 当 TIM2 厚度达数十微米时,其热阻贡献通常落在 0.1 至 1.0 °C·cm²/W。于过去晶片 TDP 仅数百瓦的时代,这样的热阻水准尚可接受;然而随着 AI 晶片局部热通量大幅提升,即使 TIM2 热阻仅为 0.1 °C·cm²/W,仍可能在介面产生高达 100°C 的极端温差,进一步推升晶片结温,使其轻易突破 80°C 至 100°C 的安全运作区间,最终导致系统降频、失效甚至崩溃。
因此,无论是传统 Cold Plate 直接液冷架构,抑或 MCCP,本质上皆面临相同的物理限制,也就是热传递路径过长,且高度依赖低导热率的 TIM2 作为关键换热介面。 MCCP 虽透过微缩冷板流道与提升对流换热效率改善整体散热表现,但仍无法绕过 TIM2 所形成的主要热阻瓶颈。只要此介面层仍然存在,系统便难以实质突破高功率 AI 晶片的散热限制,而这也正是业界进一步发展 MCL 架构的根本原因。
MCL 一体化架构将大幅缩短热传导路径
| 层级(由上至下) | Cold Plate DLC | MCCP | MCL |
|---|---|---|---|
| 冷却液循环层 | Cold Plate(一般通道 ~150 μm) | Cold Plate(微通道 80–100 μm) | 消除 |
| TIM 2 | 存在 | 存在 | 消除 |
| Heat Spreader | 存在 | 存在 | 消除 |
| 换热核心 | Cold Plate 独立于封装外 | Cold Plate 独立于封装外 | Micro-channel Lid 整合换热 |
| TIM 1 | 存在 | 存在 | 仍存在 |
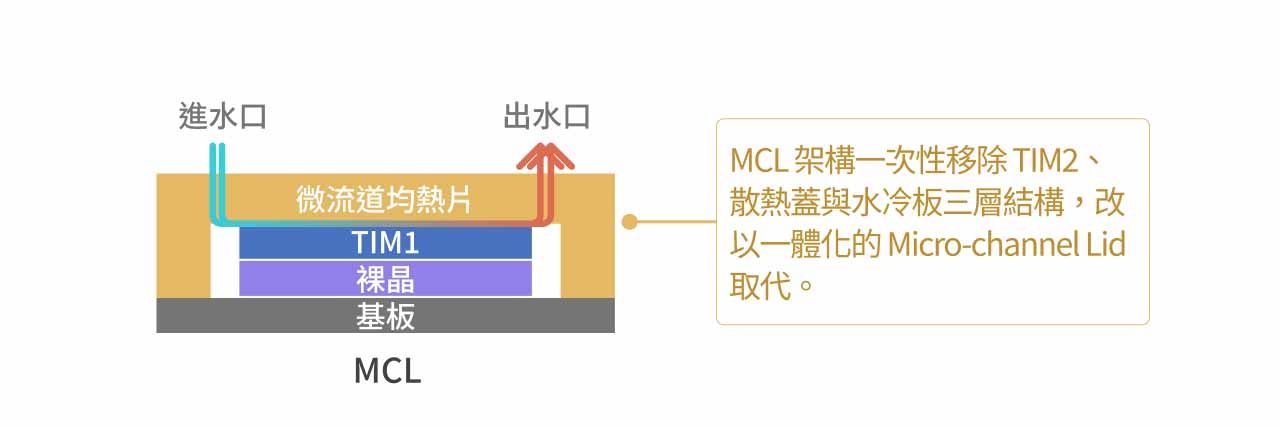
MCL 架构透过一次性移除 TIM2、Heat Spreader 与 Cold Plate 三层结构,改以一体化的 Micro-channel Lid 取代,使冷却液可直接于最接近晶片的 Lid 内部循环,借由显著缩短热传导路径以大幅降低整体热阻。 此设计将原本分离的均热片与冷水板功能整合为单一元件,即 Micro-channel Lid(微流道均热片)。由于该结构本身即内建冷却流道,可完全消除传统架构中 TIM2 所形成的关键热阻瓶颈,因而被视为未来 AI 伺服器突破高功耗散热限制的重要技术方向。
MCL 散热路径解析(由下至上):
- 晶片发热(SoC & HBM)。
- 热量传导至第一层散热介面材料 TIM 1。
- 热量直接进入 Microchannel Lid,冷却液直接在紧贴着 TIM 1 的微小流道中循环,迅速带走热量。
就目前学术文献而言,Lid-integral 微通道冷却模组已具备具体实测数据可供参考。传统微通道冷板,也就是 MCCP 类型,其热阻大致落在 0.07 K/W 等级,实测结果显示,相较于一般宏观通道冷板,微通道冷板可提升约 50% 的散热效能。至于 MCL,由于进一步移除 TIM 2 与 Heat Spreader,理论上相较于传统 Cold Plate 直接液冷架构,最高可带来约 3 倍的散热效能提升,从而更有机会支撑 2.3 kW 以上 AI 晶片的高功耗散热需求。
| 指标 | 数据 | 来源 |
|---|---|---|
| 晶片到冷却液入口的热阻 | 27.1 mm²·K/W | ScienceDirect,Lid-integral 微通道模组实测(流量 1 L/min) |
| 晶片表面最大温差 | 6.3°C(实测)/ 4.1°C(模拟优化后) | 同上,热通量 150 W/cm² 条件下 |
| 压降 | 18.3 kPa(流量 1 L/min) | 同上 |
| 微通道尺寸 | 通道深度 250 μm、宽度约 210 μm | 同上 |
均热片技术延伸价值浮现,成为 MCL 量产关键门槛
MCL 虽在硬体架构上移除了传统均热片,但这并不代表均热与保护功能自此消失,反而是将两者全面整合至 Micro-channel Lid 本体之中,并使其成为设计上最隐性、也最难突破的核心技术门槛。在传统冷板架构下,均热片表面上仅是一层金属盖板,实际上却同时肩负保护脆弱裸晶与均匀扩散热点两项关键任务。其一方面作为矽晶结构抵御封装机械应力与反复热胀冷缩的第一道防线,另一方面则凭借高导热特性,先行将 AI 运算过程中 SoC 与 HBM 所产生的局部极端热点加以扩散,避免热量在未经均热处理下直接冲击换热介面,进而削弱整体冷却效率。
当 MCL 将封装盖板与换热器整合为单一结构后,工程师必须在一片极薄的金属基材上,同时平衡多项高度冲突的设计要求。该基材不仅需具备足够的热扩散能力,以避免局部过热,亦必须在内部精准加工出 80 至 100 微米等级的微流道,以确保流量分布均匀并将压降控制在可接受范围内。 更具挑战性的是,极细流道的导入不得削弱整体结构强度,仍须足以承受封装制程中的外力负载,以及数万次热循环所累积的疲劳应力,而不产生变形或裂损。
此外,考量冷却液长期流经微流道可能造成微粒沉积与堵塞风险,而 MCL 一旦受损,亦无法如传统冷板般单独拆换,往往意味着整颗高价 AI 晶片必须一并报废,因此其长期可靠度验证标准远较传统架构更为严苛。 为降低因流道大幅微缩所带来的堵塞风险,系统过滤能力亦必须同步提升至 10µm 以下,方能支撑长期稳定运作。然而,若直接将 CDU 内部过滤器升级至此等级,又将进一步推升系统压降、泵浦功耗与滤芯更换频率,反映出液冷散热架构朝 MCL 演进的同时,过滤系统升级亦已成为不可避免的配套方向。整体而言,上述任一设计条件若出现失衡,皆可能导致良率显著下滑或产品失效,这也正是 MCL 开发周期远较传统冷板更长,且良率迄今仍为量产最大瓶颈的根本原因。
在此背景下,散热产业中已发展多年的均热片技术,于迈向 MCL 时代的过程中展现出新的延伸价值。长期深耕均热片制造的厂商,凭借在以下四项工程能力上的技术累积,正好具备切入 MCL 量产体系的重要基础,并形成关键进入门槛:
- 金属材料特性: 包含无氧铜的热膨胀系数、反复热循环下的疲劳行为,以及与不同 TIM 的界面相容性。这些材料特性评估可直接应用于 MCL 的 Lid 基材选用与结构设计中,以降低流道结构在长期热循环后因疲劳积累而失效的风险。
- 电镀制程控制: 均热片表面电镀层需维持均匀、致密及良好的基材结合力,以避免在热循环中发生剥离。MCL 的微流道内壁同样需要精密的电镀处理来提升抗腐蚀性与导热性,两者在良率控制的逻辑上具备高度共通性。特别是在 Rubin 世代采用石墨/铟复合材料作为 TIM 2 后,因其对 Lid 表面具腐蚀性,电镀层的品质控制更显重要。
- 封装结构力学: 均热片在封装过程中需承受来自基板翘曲、晶片压合与固晶应力的多向力矩,厂商需对封装件整体的力学行为有充分掌握。MCL 作为封装结构的一环,亦面临类似的挑战,且因整合了流道设计而增加复杂度。随着晶片尺寸放大,翘曲风险随之提高,对封装结构力学的标准也相应提升。
- 热点扩散设计: 均热片的设计重点在于如何在有限面积内将局部热点均匀扩散。此设计逻辑同样适用于 MCL,若 Lid 底部无法有效分散热源,将会限制微流道的整体散热效率。热点扩散的设计经验,构成了均热片厂商在 MCL 开发上的技术基础。
机会厂商
健策 (3653)
公司简介
健策精密工业早期由精密模具与电子零件起家,现已聚焦高阶散热解决方案,核心产品包括高阶均热片、LED 导线架及车用 IGBT 散热模组,并提供整合 CPU 扣件、均热片与水冷板的一站式客制化散热方案。 公司具备模具开发、冲压及半导体级电镀表面处理等垂直整合能力。
以 2025 年营收结构来看,散热相关产品占比达 73%,为主要营收与获利来源。 主要客户涵盖台积电、日月光投控、AMD、Intel 与 Nvidia 等全球晶圆代工、封测及晶片设计大厂,前几大客户合计营收占比逾 70%,水冷板产品亦已切入 Supermicro 等伺服器系统厂供应链。
竞争优势:跨足封装设计、精密制造与电镀量产,健策具备切入 MCL 的先发基础
在液冷技术持续升级的趋势下,供应商必须同时具备机械加工与半导体封装的跨领域能力。健策目前已切入 NVIDIA GPU 均热片,以及台积电 CoWoS 封装所需的 Lid 与 Stiffener 供应链,并累积了在晶片设计初期即参与几何规格、材料选择与介面定义的实务经验。就 MCL 技术发展而言,健策凭借其封装设计能力、大规模电镀量产基础及与客户长期合作关系,已具备一定竞争优势。考量 MCL 量产对电镀精度与封装结构力学的要求更高,健策可望延伸其长期累积的精密冲压能力,以因应微流道加工精度需求,并透过垂直整合电镀产线强化良率控管,同时将既有 CoWoS 封装经验应用于解决更复杂的结构力学挑战。
| MCL 关键制程门槛 | 健策对应能力 | 能力来源 |
|---|---|---|
| 微流道蚀刻精度 | 精密冲压 + 长年制造均热片薄壁结构 | 均热片量产 30+ 年积累 |
| 电镀制程良率 | 自有电镀产线,熟悉铜基材电镀层均匀性 | 垂直整合电镀制程 |
| 封装结构力学 | TSMC CoWoS Lid/Stiffener 核心供应商 | 封装 Lid 长期合作 |
| 热点均散设计 | 均热片设计核心能力,直接移植至 MCL | 均热片 R&D 积累 |
| 客户设计早期参与 | NVIDIA GPU 每一世代均从设计初期参与 | 唯一供应商地位 |
成长动能 1 :Rubin 世代规格升级带动 ASP 上行,并为健策 MCL 量产奠定技术基础
MCL 预计要到 2027 年下半年至 2028 年才会开始带来较明显的营收贡献。在此之前,2026 年下半年推出的 Rubin 世代可视为均热片走向液冷整合的过渡阶段,产品规格、制程难度与单价均明显提升。由于 Rubin 采双晶片设计,封装尺寸放大,Stiffener 为避免热循环下翘曲开裂,规格要求同步升级,单价预估将较过往提升。同时,因应新型 TIM2 材料特性,Lid 也升级为双片式设计,并加入薄金电镀保护制程,带动单价较 Blackwell 世代进一步提升。Rubin 双片镀金 Lid 在电镀精度、表面处理与结构设计上的要求,亦与未来 MCL 制造技术高度相关,相关量产经验可望成为健策后续切入 MCL 的重要基础。
| 时程 | 产品 | ASP 相对水准 | 确定性 |
|---|---|---|---|
| 现在 | B300 均热片(石墨烯) | 基准(20–25 美元) | 量产中 |
| 2026 H2 | Rubin Stiffener + 双片镀金 Lid | 数倍(Stiffener 20–30 USD) | 3Q26 放量 |
| 2027 | CPO Stiffener(Spectrum-5 / Q5) | 30–60 美元/组 | 设计确认 |
| 2H27–2028 | 微流道均热片(MCL) | 现行方案 7–10× | 设计待定案 |
成长动能 2 :健策同步跨足 CPO 与车用散热成为中长期成长动能
除了 AI 业务外,健策亦将封装件结构强化设计能力延伸至 CPO 领域,并有望成为 NVIDIA Spectrum-5 与 Quantum-5 交换晶片 Stiffener 的主要供应商。该业务预期可于 2027 年贡献约 10% 的新营收占比,反映公司技术能力已可同步切入运算与网通两大市场。另一方面,非 AI 业务中约占营收 16% 的 IGBT 散热模组,则受惠于全球电动车渗透率提升,持续提供相对稳定且独立于 AI 产业周期之外的营收来源。
元钛科 (7892)
公司简介
元钛科技成立于 2022 年,专注于液冷设备与系统整合解决方案,核心产品包括 CDU、Sidecar 及客制化 SI 案场服务,主要聚焦资料中心与机房二次侧系统建置。 公司增资后股本为 4.69 亿元,并于 2026 年 1 月 16 日以 238 元登录兴柜。主要客户包括鸿海旗下鸿佰、纬创、纬颖,亦服务瑞昱、慧荣及创意等 IC 设计公司之实验室与机房建置需求。
竞争优势 1 :提前布局 CDU 与 Sidecar,相较同业具成本优势及新产品开发能力
元钛科的竞争优势在于,其产品布局正位于液冷系统由过渡方案迈向完整水对水架构的核心位置。 随着伺服器机柜热功率持续提升,液冷架构已由风扇背门与 Sidecar 等水对气方案,逐步升级至以 CDU 为核心的水对水系统;而在直接液冷与 MCL 技术持续渗透下,晶片端导热效率虽明显提升,却也同步拉高系统端对冷却液循环、热交换效率与整体稳定性的要求。元钛科凭借 Sidecar 与 CDU 的产品布局,成功掌握此一系统级散热升级趋势,成为液冷供应链中具关键地位的设备供应商。另一方面,CDU 为液冷系统中价值最高的核心设备之一,单价可达 5 至 15 万美元,且随设备功率由 600kW、1.3MW 升级至 2.5MW,并进一步朝 4MW 发展,带动产品售价与技术门槛同步提升,形成量价齐扬的成长结构。相较国际同业,元钛科具备约 15% 至 20% 的成本优势,有助于其在市场扩张过程中强化价格竞争力与市占率;同时,公司亦积极投入负压式 CDU 等新产品开发,进一步巩固未来 3 至 5 年的成长潜力。
竞争优势 2 :兼具设备制造与系统整合能力,以一站式方案提升专案价值与客户黏着度
| 上游 | 中游 | 下游 |
|---|---|---|
| 土地、基础设施等供应商 | 资料中心设计 & 建置规划机房、机柜产品、资讯安全、设施管理等 元钛 (7892.TW) | 电脑机房、资料中心、伺服器代工及品牌厂等 |
元钛科另一个竞争优势在于其兼具设备制造与资料中心系统整合能力,并非仅是单纯的设备供应商。此一商业模式使公司得以由单一产品销售,进一步延伸至整体机房规划与建置,提升单一客户专案的整体价值。 当元钛科承接资料中心建置案时,除可认列工程收入外,亦可同步带动 CDU 与 Sidecar 等液冷设备销售,形成设备与工程绑定的一站式解决方案,进一步放大营收规模与客户黏着度。
此外,随着散热技术由系统级液冷进一步走向封装级 MCL,液体流动、压力控制、热交换效率、漏液风险与系统稳定性的重要性持续提升,市场需求也将更倾向具备整体解决方案能力的供应商。元钛科除提供 CDU 设备外,亦具备资料中心二次侧系统整合能力,可涵盖设备、管线与整体机房规划。随着 MCL 导入推升系统复杂度,元钛科一体化整合能力的重要性可望进一步提升。
成长动能 1 :MCL 推动过滤系统升级,元钛科外挂式过滤装置将成为未来水流通道微缩趋势
随着 MCL 将水流通道大幅微缩至约 80µm,虽可显著提升散热效率,但也同步提高堵塞风险。 若杂质随时间累积,将导致有效散热面积缩小、冷却效率下降,并使晶片表面温度分布恶化,进一步影响运作效能与使用寿命。目前市面上资料中心 CDU 内建过滤系统多以 50µm 为标准,即使升级选配通常也仅达 25µm,仍难以满足 MCL 所需的过滤等级。为保护 80µm 微流道并降低长期堵塞风险,过滤系统能力必须提升至 10µm 以下。元钛科则掌握此一关键技术,推出可将冷却液杂质过滤至 10µm 的外挂式过滤机台,在兼顾压降与成本控制下,有效降低杂质累积风险,并延长整体水冷系统寿命。
