商业模式介绍
NVIDIA 作为全球领先的 GPU 供应商,其成功来自于独特且完善的商业模式,核心在于完整的生态系统(Ecosystem)与有效的商业杠杆(Leverage)。
生态系统(Ecosystem)
NVIDIA 的生态系统是公司竞争力的核心基础之一。透过其自主开发的 CUDA(Compute Unified Device Architecture)平台,NVIDIA 建立了庞大且完善的软硬体整合生态圈。
什么是 CUDA? CUDA(Compute Unified Device Architecture)是一种软硬体整合技术,允许开发者利用 NVIDIA 的 GPU 进行图像处理以外的运算。NVIDIA 的生态系统以其自主开发的 CUDA 平台为核心,企图打造软硬体结合的完整生态圈。
以 CUDA 平台为核心,NVIDIA 也推出了多项先进技术和平台,试图将不同开发领域纳入生态系中,打造产品护城河。我们这里举出 NVIDIA 近期重视的几个技术和平台:
NVIDIA Drive
NVIDIA DRIVE 是自动驾驶领域的端到端平台,整合嵌入式超级计算硬体与软体开发工具,为车辆提供先进的人工智慧功能。该平台能即时处理来自摄像头、雷达和激光雷达等各种传感器的数据,实现安全可靠的自动驾驶功能。
在硬体组成方面,NVIDIA 提供的 DRIVE Hyperion 是一套完整的自动驾驶参考架构,整合了包括 DRIVE AGX 系列在内的车载运算系统与各类感测设备。此外,最新推出的 DRIVE Thor 作为 AGX 系列的最新系统晶片(SoC),基于先进的 NVIDIA Blackwell 架构打造,并首次引入推理 Transformer 引擎,进一步强化平台的运算性能与稳定性。作为 DRIVE AGX Orin 的升级产品,DRIVE Thor 展现出显著提升的效能与技术优势。
NVIDIA DRIVE 平台已被多家全球领先的汽车制造商和技术公司采用,以推动自动驾驶技术的发展。目前已知有包括 Mercedes-Benz、Jaguar Land Rover、Volvo Cars、现代汽车、比亚迪、Polestar及蔚来等知名合作厂商。
NVIDIA DLSS
NVIDIA DLSS(Deep Learning Super Sampling)技术,协助游戏开发者透过人工智慧提升游戏画质与运行流畅度,明显改善使用者的视觉体验。
该技术已获得多家知名游戏开发厂商的支持与采用,包括 Epic Games、CD Projekt Red、Activision 等。同时,NVIDIA 亦透过经销商如华硕、技嘉、微星等积极推广 GeForce GPU,以进一步提升游戏效能并拓展市场影响力。
NVIDIA Jetson
NVIDIA Jetson 是专为自主机器领域设计的嵌入式系统,为开发者提供卓越的 AI 计算效能。目前已广泛应用于机器人、无人机、自动导引车辆(AGV)、智慧零售、智慧城市监控、工业自动化、智慧医疗设备等多种自动化及智慧型设备领域。
实际应用案例包括新汉科技推出的边缘 AI 交通电脑、研扬科技的智慧视觉辨识系统,以及立普思科技(LIPS)与 Jetson 平台整合的 3D 相机解决方案。
NVIDIA Maxine
NVIDIA Maxine 为一套 AI 软体开发工具包,提供视频降噪、虚拟背景替换、面部表情重建等先进功能,旨在提升视频通讯的品质与互动体验。
目前已有多家企业采用 NVIDIA Maxine,包括腾讯云利用其 AI 绿幕功能强化云端视频服务、Looking Glass 公司将 Maxine 3D 技术融入全息视频会议应用,以及 Pexip 透过 Maxine 的音频降噪技术提升视频通讯品质,充分展现出 Maxine 技术的实际价值与多样化应用潜力。
NVIDIA Omniverse
NVIDIA Omniverse 是一个即时 3D 设计协作与模拟平台,透过整合多种不同软体工具和工作流程,协助设计师、工程师和内容创作者进行跨平台的协同合作与创作。
目前已知的实际应用有包括 BMW 集团采用 Omniverse 平台所打造的数位孪生工厂,大幅优化汽车生产与设计流程,以及知名动画公司皮克斯(Pixar)也选用 Omniverse 加速动画设计与内容制作流程。此外,亚马逊(Amazon Robotics)也透过 Omniverse 模拟并渲染虚拟的 3D 环境,试图优化仓储物流机器人的工作流程。
NVIDIA CUDA Quantum
NVIDIA CUDA Quantum 是一个开放原始码平台,旨在将量子运算与经典运算相结合。该平台提供高效能的开发环境,使研究人员和开发者能够设计、模拟及执行量子演算法,并有效整合现有的 CPU 与 GPU 资源,加速量子科技的研究与应用。此外,NVIDIA Quantum Cloud 则为用户提供强大的云端量子运算服务。
目前已有多个知名机构与 NVIDIA 合作推进 CUDA Quantum 的实际应用,包括量子技术公司 Xanadu、量子计算服务商 Pasqal,以及量子算法开发商 Classiq。
 资料来源: NVIDIA Keynote at COMPUTEX 2023直播
资料来源: NVIDIA Keynote at COMPUTEX 2023直播
推广开源生态圈
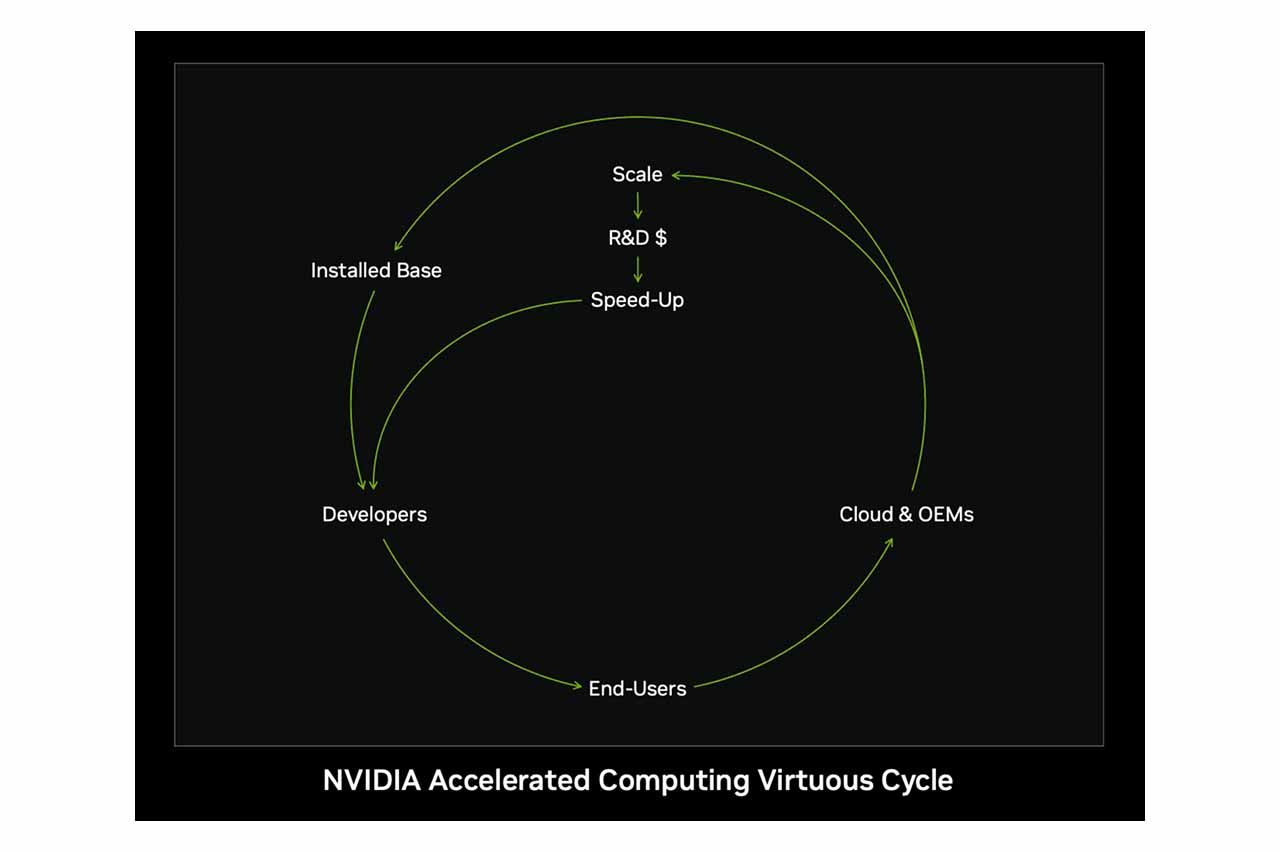
NVIDIA 也积极透过开放合作与平台生态圈推广,透过与全球软硬体企业建立广泛的技术合作,迅速切入不同的垂直市场,将核心技术有效落地于实际产品和解决方案中。这也有效地让 NVIDIA 可以快速的适应 AI 浪潮下产品的快速变动。
- 与 AWS、Google、Microsoft 等科技巨头合作,共同推动云端 AI 服务。
- 与学术界及研究机构合作,共同培养新一代技术人才,进一步扩大生态圈的影响力。(成立深度学习学院 DLI)
这种全面的生态系统策略,不仅有效降低客户转换成本(Switching Cost),更提高了客户的忠诚度,形成竞争壁垒,进而巩固 NVIDIA 的市场领导地位。
商业杠杆(Leverage)
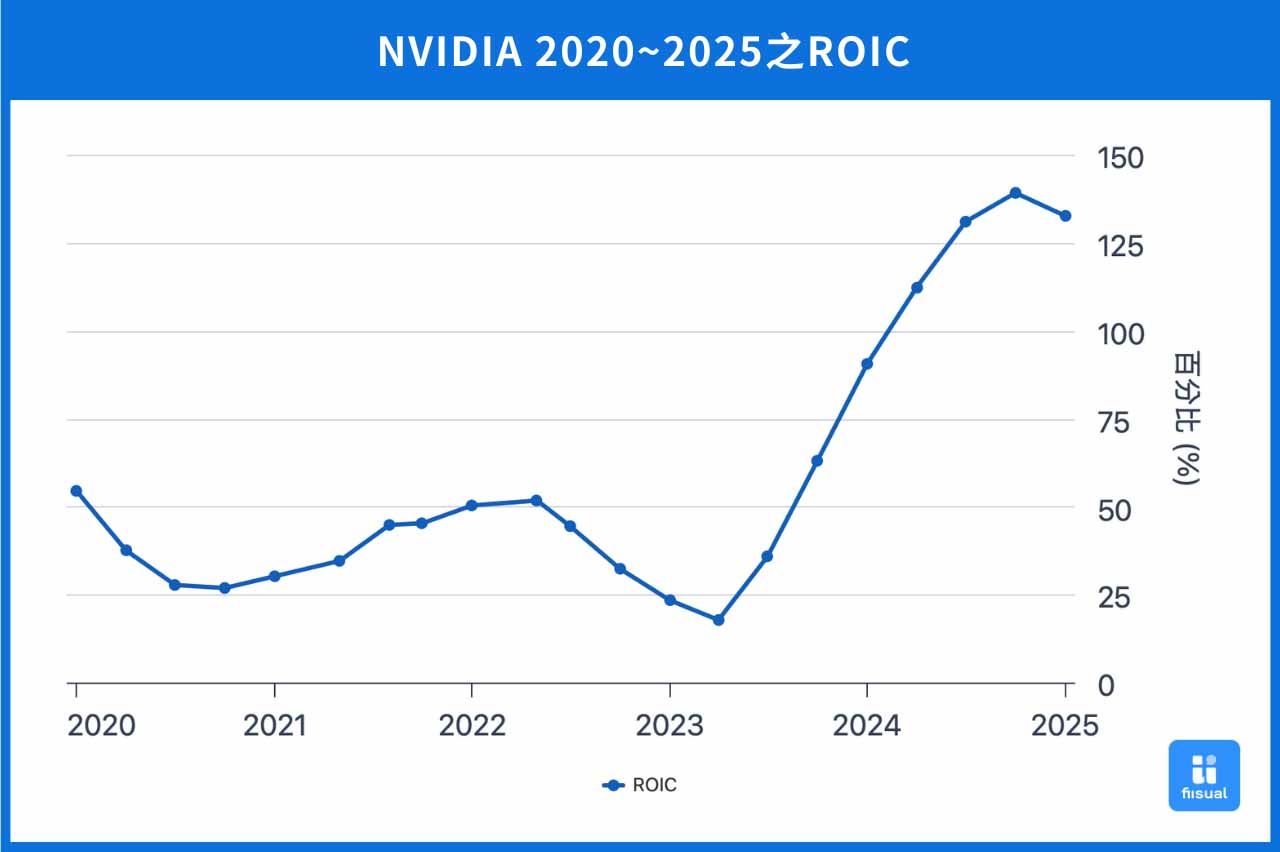
NVIDIA 的商业杠杆策略主要展现在其核心技术具备跨市场重复应用的能力,借由单一技术架构支援多个垂直市场,达到规模经济效应。例如,以 GPU 为核心的技术架构,不仅广泛应用于游戏市场,亦能延伸至人工智慧(AI)计算、自动驾驶技术、虚拟实境(VR)及资料中心等多元领域。这种跨市场重复运用的策略,使 NVIDIA 能有效提高产品开发的投入资本报酬率(ROIC),降低各市场进入时的风险,并透过研发成本的分摊,进一步降低产品的单位成本,增强企业竞争优势。
具体而言:
- GeForce 系列专注于游戏市场。
- Quadro 系列专注于专业图形与办公应用。
- Iray 系列则应用于虚拟实境(VR)。
- DRIVE 系列聚焦于自动驾驶。
- Hopper 和 Blackwell 系列则用于数据中心与高效能 AI 运算。

透过这种技术杠杆模式,NVIDIA 得以迅速切入新兴市场,扩展收入来源。例如:
- 原先专为游戏设计的 GeForce GPU 架构经过调整与优化后,成功跨足 AI 计算(如 Tesla、Blackwell 系列)与汽车自动驾驶市场(如 Drive 系列)。
- 利用 GPU 强大的平行运算能力,在深度学习市场兴起后,迅速成为全球 AI 运算领域的主要解决方案提供商。
综合以上,NVIDIA 透过完整的生态系统与有效的商业杠杆模式,不断强化自身竞争力并创造长期价值。未来,随着 AI 与自动驾驶的普及,这一模式将持续带来巨大的成效,使 NVIDIA 进一步提升市场影响力与竞争优势。
产品线介绍及布局
NVIDIA透过多元化的产品线布局,以满足不同市场需求,产品线主要涵盖游戏、人工智慧及资料中心、自动驾驶等领域。
游戏用 GPU:GeForce 系列

GeForce 系列是 NVIDIA 专为游戏玩家打造的 GPU 产品,以卓越的图形渲染能力与高效能运算表现,提升游戏的流畅性和视觉效果。例如最新的 GeForce RTX 5090、5080、5070 等 GPU,均搭载最新的 Blackwell 架构,具备先进的光线追踪技术(Ray Tracing)与 DLSS 4 技术,大幅提升游戏画面的逼真度与效能,广泛应用于 AAA 级游戏及高解析度游戏需求。
AI 应用 GPU:Hopper & Blackwell
Hopper 系列

Hopper 架构专为高效能 AI运算 设计,应用于深度学习训练、HPC(高效能计算)与企业 AI 推理。旗舰产品 H200 GPU 搭载 Transformer Engine,显著提升 AI 训练与推理效率,特别适用于 GPT、BERT 等 AI 模型。Hopper 仍为 HPC 与云端 AI 推理的主流选择,但随着 Blackwell 架构 推出,市场需求逐步转向更高效能解决方案。
Hopper 架构特色
- 第一代 Transformer Engine:加速 AI 训练与推理,特别针对大型语言模型(LLM)。
- 第四代 NVLink:提升 GPU 之间的连结速度, 支持超大规模 AI 计算。
- HBM3e 记忆体:支援更高频宽和更低功耗的高效能 AI 运算。
应用场景
- 超级计算机(HPC):科学研究、医学影像分析。
- 资料中心 AI 计算:云端 AI 服务、AI 模型训练与推理。
- 企业 AI 解决方案:自动语音识别、影像分析等。
Hopper 架构虽然仍在市场上占据重要地位,但随着 Blackwell 架构(B200、GB200) 的推出,H200 的需求逐渐转向较成熟的 AI 计算与资料中心应用。
Blackwell 系列
Blackwell 架构是 NVIDIA 最新 AI GPU 技术,专为 生成式 AI、大型语言模型(LLM)与超大规模 AI 计算设计。B200 GPU 相较 H100 能效提升 2.5 倍,并支援 HBM3e 记忆体、NVLink 5.0,进一步降低 AI 计算能耗与成本。此外,GB200 超级晶片整合 B200 GPU + Grace CPU,提升 AI 训练与推理解决方案,适用于 Google、Meta、OpenAI 等企业的大型 AI 模型训练。
Blackwell 架构的核心产品
1. B200 GPU
- 采用 台积电 4NP 制程,内含 2080 亿个电晶体,专为 NVIDIA 高效运算需求量身打造。
- 第二代 Transformer Engine,强化 大型语言模型(LLM)与专家混合(MoE)模型 的训练与推理。
- 内建 解压缩引擎,可透过高速 NVLink 连结 NVIDIA Grace CPU,共享高达 900 GB/s 双向频宽记忆体,加速 AI 运算与资料处理。
2. GB200 AI 超级晶片
- 由两颗 B200 GPU + Grace CPU 组成,可进一步提升 AI 运算效率。
- 提供 NVL36 和 NVL72 两个版本,提高 GPU 之间的数据传输效率,降低延迟。
- 针对超大规模 AI 模型训练(如 GPT-4、Gemini 1.5) 进行优化。
Blackwell 市场趋势与影响
- 市场需求旺盛:Blackwell GPU 在 超大规模 AI 计算 领域备受青睐,Google、Microsoft、Meta、OpenAI 等企业均已部署。
- 逐步取代 Hopper:Blackwell 成为新一代 AI 运算核心,但 H200 仍广泛应用于成熟 AI 计算与 HPC 领域。
- 短期毛利率下降:由于 Blackwell 初期生产成本较高,NVIDIA 毛利率从 75% 降至 73.4%(2025 Q4),但随量产提升,毛利率有望回升。
- 成长潜力强劲:随 AI 应用需求持续上升,Blackwell 产品线预计将进一步推动 NVIDIA 资料中心营收增长。
以下是 Hopper 架构(H200)和 Blackwell 架构(GB 200)的比较表格。
| Hopper 架构 (H200) | Blackwell 架构 (GB200) | |
|---|---|---|
| 晶片制成 | TSMC 4N | TSMC 4NP 客制化 |
| 目标&应用 | 数据中心&AI 训练 | 生成式 AI&即时推理 |
| 记忆体 | 141 GB HBM3e,4.8 TB/s 带宽 | 13.5 TB HBM3e,576 TB/s 带宽 |
| Transformer Engine | 第一代 | 第二代,针对生成式 AI 和 LLM 推理优化 |
| 互联技术 | 第 4 代 NVLink,600 GB/s | 第 5 代 NVLink,1.8 TB/s |
| 效能提升 | 相比 H100 提升约 1.9 倍 | 相比 H100 提升高达 30 倍(推理性能) |
| 能耗管理 | 最大 TDP 700W | 最大 TDP 1200W(NVL72 配置) |
| 超级晶片 | 无 | GB200(B200 GPU + Grace CPU) |
| 适用场景 | HPC、资料中心、企业级 AI | 生成式 AI、大型LLM、超大规模 AI |
产品竞争优势
市占率远超同行,生态系是关键
 辉达资料中心 GPU 市占率高达 92%,相当惊人。
辉达资料中心 GPU 市占率高达 92%,相当惊人。
随着 AI 发展加快,晶片需求也日益增长当中。GTC 大会上,黄仁勋表示美国四大 CSP 厂于去年购买了 130 万个 Hopper 架构晶片,又于今年购买了 360 万个 Blackwell 架构晶片,显示下游算力囤积量惊人。而根据 IoT Analytics 的市场份额调查,截至 2025 年 3 月,辉达于资料中心 GPU 全年市占率高达 92%,而第二大的 AMD 仅占据4%,辉达在资料中心 GPU 市场中独占鳌头。
辉达之所以能达到如今地位,很大一部分归功于旗下强大的 CUDA 平台。CUDA(Compute Unified Device Architecture)首次于 2006 年推出,作为一个运算平台与程式设计模型,其成功实现 GPU 从图形渲染到通用计算的创新突破。开发人员得以运用工具如:C、C++等,编写程式码将较复杂、大量的计算需求透过 CUDA 转交 GPU 执行,使 CPU 与 GPU 可以发挥各自优势,有效分工。随着 AI 爆炸式的发展,晶片承载的计算量日益增加,CUDA 给予使用者最大的调整弹性 ,成为 GPU 得以在不同领域计算发挥最大效能的关键。由于 CUDA 只供给辉达自家的晶片运行,方便的功能与多年的耕耘亦累积了不少忠实用户,建构辉达现今的核心护城河。
技术与算力为当前顶尖
目前市场上第二大的半导体公司为 AMD,而多年的对手 Intel 也正积极拓展资料中心 GPU 市场当中。以下为辉达与市面上其他的晶片比较:
| GB200 | MI 300x | Guadi 3 | |
|---|---|---|---|
| 公司 | NVIDIA | AMD | Intel |
| 构造 | 由一颗 Grace CPU 与 两颗Blackwell GPU 构成 | 融合 CPU 与 GPU 于同一处理器,采用 CDNA 3 架构 | 异质电脑架构,并非 CPU 及 GPU 的集成,但仍专注于计算 |
| 算力 | 高 | 中 | 低 |
| 预估价格(美元) | 60,000 - 70,000 | 14,813 | 15,650 |
| 性价比 | 低 | 高 | 中 |
| 其他优势 | CUDA 整合平台,专为 AI 与高效能运算设计 | 性价比最高,得与辉达 Hopper 系列竞争 | 在成本控制上有明显优势 |
虽然价格不及同行实惠,但在算力与技术上辉达远超同行,再加上先前提到的护城河 CUDA,于目前算力军备竞赛中,业界主要仍向辉达购买。尽管如此,AMD MI 300 系列仍是值得关注的竞争对手,因其性价比相当优越。在 2024 年 6 月的台北国际电脑展上,执行长苏姿丰表示,2025 年将推出的 MI 325x,其记忆体容量为辉达 H200 的 1.8倍、记忆体频宽为 1.3 倍,并在 FP8 及 FP16 数据格式的算力超越 H200 1.3倍。未来也预计推出 MI 350、MI 400 等,有机会于往后以更实惠的价格及更强大的计算能力打败辉达 Hopper 系列。另外,超微旗下的 ROCm 则为开源计算平台,相对于封闭的 CUDA,ROCm 兼容旗下与其他厂商硬体开发,提供更大的灵活性。
另外,ASIC 晶片(Application-Specific Integrated Circuit)的兴起也是另一威胁。ASIC 为客制化专用晶片,下游客户多直接与 IC 设计大厂如:博通(BroadCom)等合作研发,根据自身需求创造最符合效益的晶片。ASIC 的最大优势在于高度优化的资源分配,实现功耗下降、成本控制的效果。若要发展通用计算,最终仍需依赖大厂所生产的通用晶片,但 ASIC 为市场带来了另一种可行的选择,未来两者可能共同占据市场,相辅相成。
长远而言,待资料中心市场发展更加成熟后,CSP 厂可能会更讲求成本控制,届时「性价比」将成为重要关键,可观察辉达的策略调整。
产品更新:GTC 大会
Blackwell Ultra 与 Feynman 推出,迭代快速
3 月 19 日凌晨,黄仁勋于辉达 GTC 大会上揭示最新 Blackwell Ultra 晶片,其主要为推理 AI 及代理 AI 所设计,性能为当前 Blackwell 晶片的 1.5 倍,预计于下半年上市。另外,下一代 Rubin 架构晶片将于 2026 推出,其中新一代的 Vera CPU 为当前 Grace CPU 的两倍。最后,他也惊喜宣布辉达将于 2028 年推出全新的 GPU 架构-Feynman。

除此之外,黄仁勋也一并发表了针对 AI 推理的开源模型 Dynamo,得以快速扩展 AI 的推理能力并降低成本。辉达 GPU 的迭代速度远超同行,强大的研发能力与技术也助益客户在软硬体的应用上发挥更大效益,成为领先市场的一大优势。
GB300 最新进度
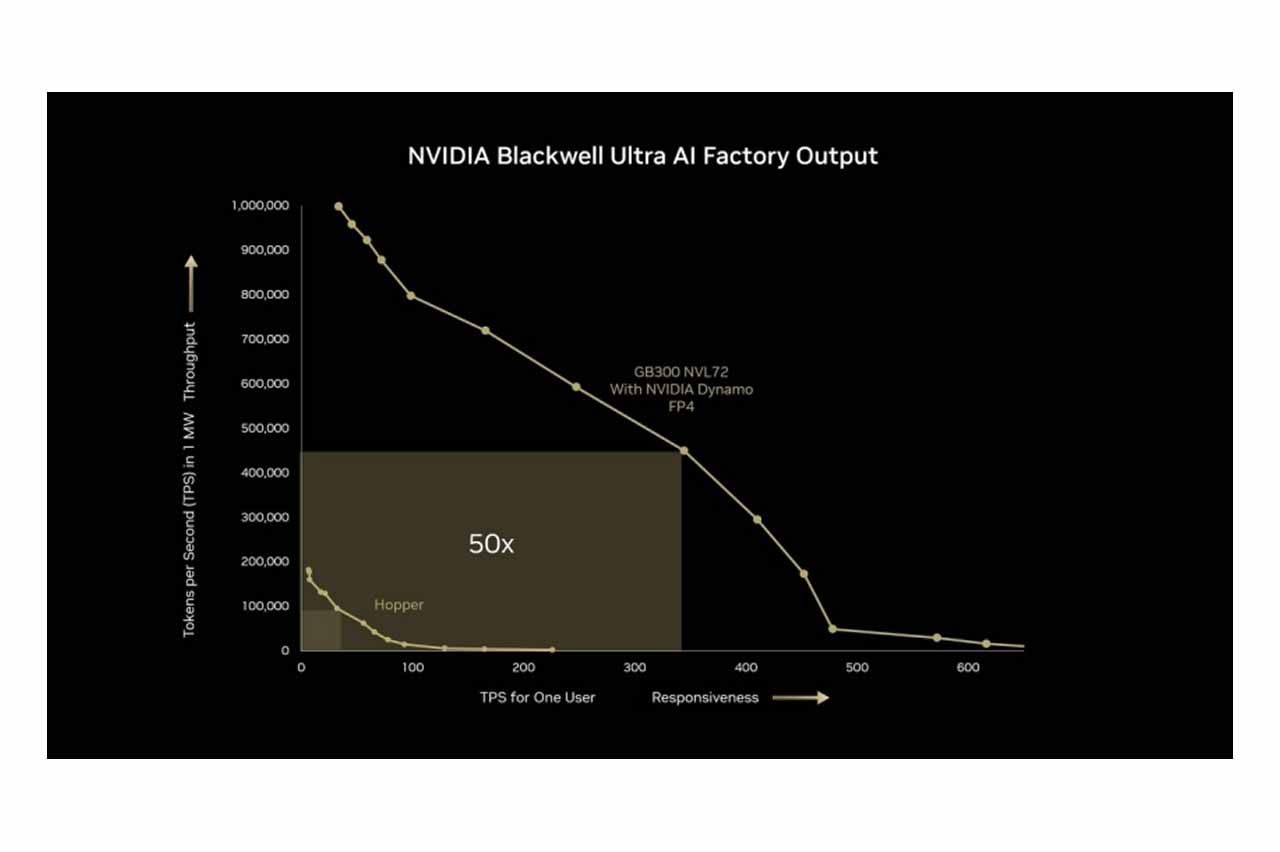
NVIDIA 预计于 2025 年下半年推出 Blackwell Ultra NVL72(GB300)机柜平台。该产品将采用 SXM7 与 Cordelia 模组设计,取代原本的 Bianca 主板,每个 Cordelia 模组整合 4 个 Blackwell B300 GPU 及 2 个 Grace CPU(共计 72 GPU、36 CPU),精简运算托盘结构并降低空间需求,提供 OEM 和 ODM 更高的整合弹性。此平台能将 AI 推理效能显著提升,用户响应速度提高 10 倍,吞吐量提升 5 倍,整体产出效能达 50 倍提升。
结论
现今,不论是资料中心或游戏领域,辉达在 GPU 市场中扮演举足轻重的角色,短期内同行难以望其项背。然而,随着技术日新月异、市场逐渐成熟,未来竞争将转移至算力成本的控制上,「性价比」为重要关键。如何活用生态圈优势留住用户而不被开源平台取代,以及价格上能否持续下修将成为辉达未来的两大挑战,而其技术演进是整个 GPU 重要的领先指标。
作为新兴发展的产业,AI 终端需求不确定性仍高,辉达的增长力道最终仍取决于终端应用是否能保持强劲。近年来,辉达也积极拓展如:自驾车、机器人等领域,透过持续不断向世界建构 AI 应用蓝图与想像,辉达得以保持终端需求无虞。对此,建议投资人应密切注意实际需求变化,以免陷入 AI 泡沫的陷阱。
