近期,中国公司幻方量化旗下的杭州深度求索人工智能基础技术研究有限公司(DeepSeek)推出了两款引人注目的模型:DeepSeek-V3 和 DeepSeek-R1。这些模型以低成本和高效能为特色,对全球科技产业产生了深远影响。
在 1 月 27 日,科技股市大幅下挫,那斯达克指数下跌 3.1%,标普 500 指数下跌 1.5%,其中 AI 晶片供应商Nvidia(NVDA)股价重挫近 17%,市值单日蒸发约 6000 亿美元。市场上开始出现并放大一些问题的声量:DeepSeek 的低成本模型是否相削弱美国科技巨头在 AI 赛道上的领先优势,并对 Nvidia 等算力供应商的真实需求提出质疑。
今天就跟着 fiisual 小编一起来了解 DeepSeek 的技术和成本,以及未来对 AI 产业有着什么影响吧!
Deepseek 核心技术
多专家机制(Mixture-of-Experts, MoE)
DeepSeek-V3 采用了一种名为 MoE 的架构,针对不同的输入选择性地活化部分专家,已提高模型的效率。因此,尽管在 MoE 架构下包含了约 6710 亿个参数,但每次推理可能仅会启用其中的 370 亿个参数,约仅有 5%。这种设计大幅降低了计算资源的消耗,同时保持了模型的高效能。
动态知识唤醒
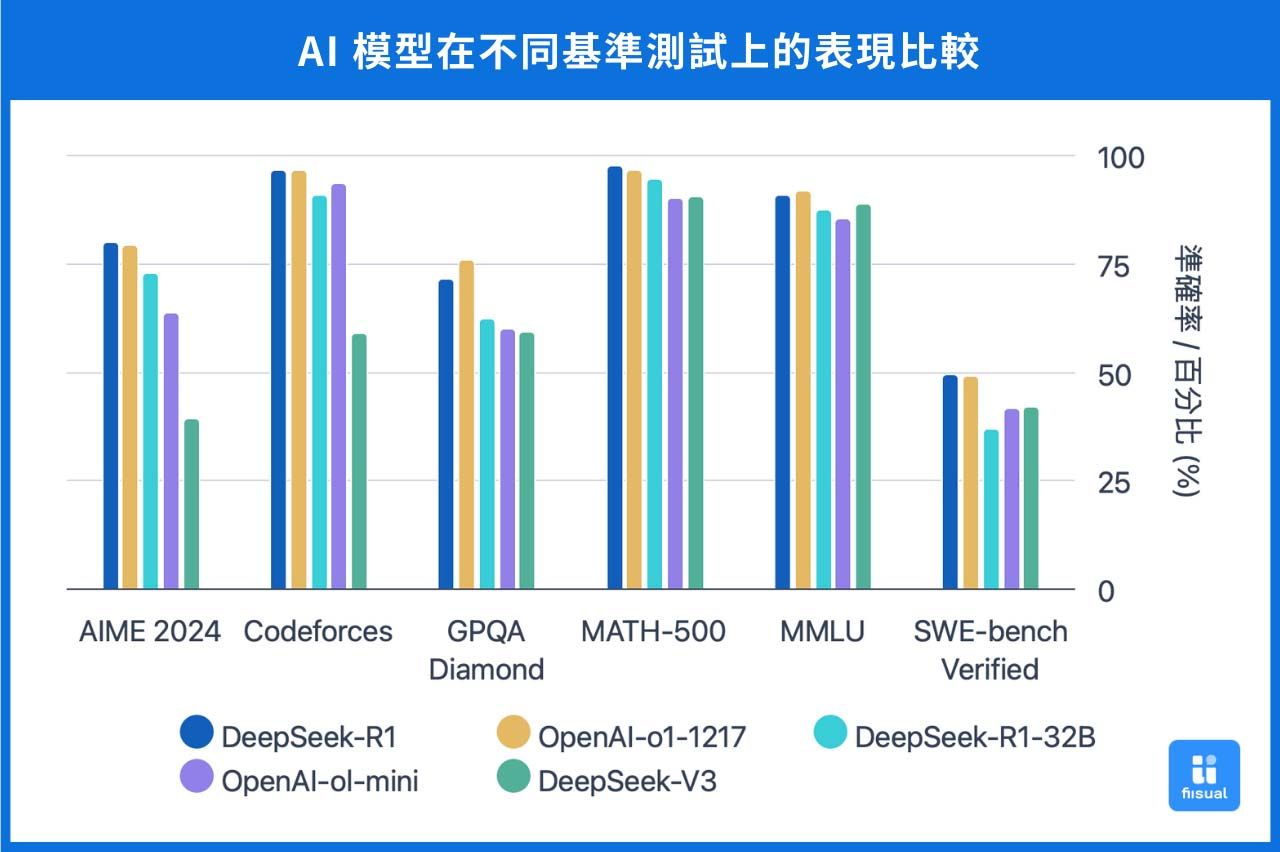
根据现有资料,DeepSeek-V3 在 MMLU(Massive Multitask Language Understanding)基准测试中取得了 87.1% 的准确率,显著优于前代模型 DeepSeek-V2 的 78.4%,并接近闭源模型 GPT-4o(约87.2%)和 Claude-3.5-Sonnet(88.3%)的水平。其独创的「动态知识唤醒机制」,能够透过动态调整模型注意力分布的方式,根据输入内容及上下文,自动调用不同的专业知识模组,提高模型的感知力及准确率。例如在处理 AIME 2024 数学竞赛题目时,模型会优先启动数理逻辑专家模组,确保推导过程的严谨性。
长文本处理能力
结合分层注意力与语境压缩技术,V3 在 LongBench v2 测试中,对 10 万字符长文本的关键信息提取准确率达 92.7%,较 GPT-4o 提升 14%。这项突破得益于其创新的记忆单元分区管理系统,能将不同类型的上下文信息(如事实数据、逻辑链条、任务指令)进行物理隔离存储,避免信息干扰。
分层注意力(Hierarchical Attention): 这种机制透过多层次的注意力结构,让模型能够在不同的层级上捕捉文本的全局和局部资讯。具体而言,模型首先将文本划分为较大的区块,以识别关键部分;然后,在这些关键区块内,进行更深入的注意力计算,以提取其中的核心资讯。这种分层处理方式,有助于模型同时掌握全局上下文和细节内容。
语境压缩(Context Compression): 在处理超长文本时,直接分析整个内容会消耗大量资源。语境压缩技术透过压缩记忆机制,将之前的上下文资讯浓缩为精简的表示,保留关键内容,舍弃多余资讯。这样,模型在处理新资讯时,可以有效利用压缩后的记忆,减少计算量,同时保持对长期上下文的理解。
中文语言能力
根据现有资料,DeepSeek-V3 在中文事实性知识测试中展现了不错的表现。在 C-SimpleQA 基准测试中,DeepSeek-V3 的准确率达到 89.3%,较 Qwen2.5-72B 高出 8%。一成就主要归功于其针对中文语境开发的语义网格技术,该技术增强了模型对中文成语、方言及专业术语的理解能力,使其达到母语专家的水准。
语义网格: 语义网格是一种技术,将语义技术与网格计算相结合,希望能够透过语义的描述和关联标注,实现资源利用的高效。它透过语义标注和本体论等手段,提升资源的可发现性和互操作性,使得资源能够被更精确地检索、整合和利用,从而提高计算和资料处理的效率。 DeepSeek 针对了 Hopper 架构的 GPU 进行深度优化,并通过了 NVLink 与 RDMA 的调度工作,在 H800 集群上实现了160GB/s 的节点内带宽与 50GB/s 的跨节点带宽。
Deepseek 模型
根据上述的核心技术框架,DeepSeek 近期推出了三款具有代表性的模型,展示了其在人工智慧领域的技术创新:
DeepSeek-V3
DeepSeek-V3 是一款通用模型,采用了「专家混合」(Mixture of Experts,MoE)架构,总参数量达到 6710 亿。每个输入仅激活 370 亿参数,实现高效推理和运算能力。此外,该模型引入了多头潜在注意力(Multi-head Latent Attention,MLA)技术,通过低秩联合压缩,减少键值(KV)快取需求,提升推理效率。
DeepSeek-R1-Zero
DeepSeek-R1-Zero 是首个完全通过强化学习(Reinforcement Learning,RL)训练的基础推理模型,无需监督式微调(Supervised Fine-Tuning,SFT)标记资料。该模型具备自我验证和反思等特性,展示了以 RL 为核心的推理 AI 发展潜力。然而,由于缺乏 SFT,R1-Zero 的输出可能存在可读性差、语言混乱等问题。
DeepSeek-R1
为解决R1-Zero的不足,DeepSeek-R1 在其基础上引入了少量标记资料和多阶段的强化学习流程。首先,使用少量高品质的思维链资料对模型进行微调,然后进行两阶段强化学习,以提高输出内容的可读性和一致性。DeepSeek-R1 在多项测试中表现出色,其推理能力可与 OpenAI 的 o1 模型相媲美。
这些模型的推出,展示了DeepSeek在降低成本的同时,提升 AI 模型效能的技术实力,对 AI 产业格局产生了深远影响。
技术成本分析
DeepSeek 因较先进的 H100 晶片遭到美国的出口管制,声称其 V3 模型仅使用较旧的 H800晶片 (相近的运算效能,但网路频宽较低),总训练成本仅为 557.6 万美元,对比 Meta 的 Llama 模型、Anthropic 的 Claude 模型,成本都为其十倍以上。
| 品牌 | 模型 | 成本 |
|---|---|---|
| DeepSeek | DeepSeek-V3 | 557.6万美元 |
| Meta | Llama3.1-405B | 9252万美元 |
| ChatGPT | GPT-4 | 7087.5万美元 |
然而,DeepSeek-V3 模型在许多问题的回答方式与 ChatGPT 有相当高的相似度,引发市场对DeepSeek 是否在预训练 (Pre-tra ining) 阶段中,透过知识蒸馏 (Knowledge Distillation) 技术,使用 OpenAI 模型作为教师模型 (Teacher Model) 以提升 DeepSeek 模型推理能力的讨论。
知识蒸馏(Knowledge Distillation): 知识蒸馏是一种机器学习技术,用来把大模型的知识「压缩」到一个小模型里,让它变得更轻量、运行更快,但仍然能保持接近大模型的效果。
我们可以把大模型想像成一个老师,而小模型就是学生。当一名优秀的老师能够清楚地将核心概念教给学生时,学生便能减少在学习上所需要耗费的资源,并尽量达到老师的水准。
OpenAI 的高级顾问 David Sacks 曾表示,DeepSeek 可能复制了 ChatGPT 的技术。另外也曾有内部人士透露,OpenAI 内部有证据显示,一些中国的公司试图透过蒸馏的方式达到复制模型的效果,这可能违反了 OpenAI 的服务条款。
影响分析
AI 硬体设备
DeepSeek 的出现不仅使蒸馏技术在 AI 模型开发中获得更多关注,提升了以小型模型提供高效能的可行性,同时也引发了市场对 AI 硬体需求的重新评估。
短期来看,由于 DeepSeek 采用如 H800 等较低成本硬体并透过技术创新降低算力需求,市场对高阶 GPU(如 H100)的需求期待可能出现松动,这也是 Nvidia 的股价在消息公布后出现下跌的主因。
然而,有些专家持乐观态度,认为技术创新降低了 AI 模型的运算成本并提升效率,这将激发更多应用场景和需求,进而推动 AI 硬体需求的增长,就如同杰文斯悖论(Jevons Paradox)所描述下技术成长和资源再投入的关系。因此,硬体供应商的长期需求曲线可能持续上升,AI 生态系统的规模也有望不断扩大。
杰文斯悖论(Jevons Paradox): 经济学理论,指的是当技术进步提高了资源使用效率时,反而可能导致该资源的总消耗量增加。原因是因为资源效率的使用提升后,会降低单位使用成本,进而刺激更多的需求,使得资源消耗反而超过原水平。
英国经济学家威廉・杰文斯(William Jevons)在其著作《煤炭问题》中提出了他对于蒸汽机技术的观察。他观察到虽然瓦特改良了蒸汽机的技术并大幅提升其使用效率,但英国的煤炭消耗量却随之大幅增加。
市场态度
AI巨头表态
OpenAI
OpenAI 在 1/31 发布 o3-mini 模型,市场解读颇有为抗衡 DeepSeek-R1 的推理模型的意味。同时,部分公司内部人士也指控 DeepSeek 侵权,然而 OpenAI 执行长 Sam Altman 在近期表示,公司目前「没有计划」对 DeepSeek 在内的中国 AI 新创公司提起诉讼。他强调,OpenAI 的重心仍然放在打造优质产品,并透过技术实力维持业界领先地位。
Anthropic
Anthropic 执行长 Dario Amodei 表示:「DeepSeek 生产的模型性能接近 7-10 个月前的美国模型,但成本更低,且成本降低为可预期的,只是第一个展示的是中国公司。」他认为 DeepSeek 仍不足以构成威胁,市场上的担忧过大,但同时也呼吁应严格执行晶片出口管制,将美国暂时的领先转化为持久的优势。
想看更多AI 相关的文章吗? 新闻专题:OpenAI 最新产品更新
